AI Unpacked #1
Het geheim van AI: waarom een 'domme' tekstvoorspeller zo slim lijkt


AI unpacked: daar waar de hype ophoudt
We worden overspoeld met verhalen over artificial intelligence (AI). Elke week lijkt er een nieuw model te zijn: GPT Deep Research, Musk's Grok3, Deepseek uit China, Gemini... Het is alsof AI de wereld gaat overnemen. Maar weinigen begrijpen wat er écht gebeurt onder de motorkap.
In deze nieuwsbrief duik ik wekelijks onder de oppervlakte van AI. Geen marketingverhalen of sciencefiction, maar een nuchtere blik op wat AI wel en niet kan betekenen voor jouw organisatie. Want alleen als je begrijpt hoe het écht werkt, kun je bepalen waar het waardevol kan zijn - en waar niet.
We beginnen bij het begin: waarom AI helemaal niet zo 'intelligent' is als je denkt - en waarom dat geen probleem is.
De realiteit achter de hype
Om door de hype heen te prikken, moeten we eerst begrijpen wat AI eigenlijk doet. Het wordt vaak gepresenteerd als één technologie, maar AI kent verschillende toepassingsgebieden. De meest bekende zijn beeldherkenning (handig voor het opsporen van verdachte bagage op Schiphol), spraakherkenning (dankzij Siri weten we allemaal hoe goed dát werkt...), en natuurlijke taalverwerking - oftewel Natural Language Processing (NLP).
NLP is het vermogen van computers om menselijke taal te verwerken. En dan bedoel ik niet alleen het herkennen van woorden, maar ook het begrijpen van de betekenis en context. Tenminste, dat is wat de marketeers van grote techbedrijven je willen doen geloven. In werkelijkheid is NLP gewoon een fancy term voor 'tekst analyseren en genereren'.
Maar onderschat dit niet. Net zoals een Instagram-filter geen échte fotografiekennis heeft maar wel verbluffende foto's kan maken, kan NLP zonder echt 'begrip' toch indrukwekkende dingen doen met tekst. Het is als een ongelooflijk krachtige tekstverwerker die patronen herkent op een schaal die we ons nauwelijks kunnen voorstellen.
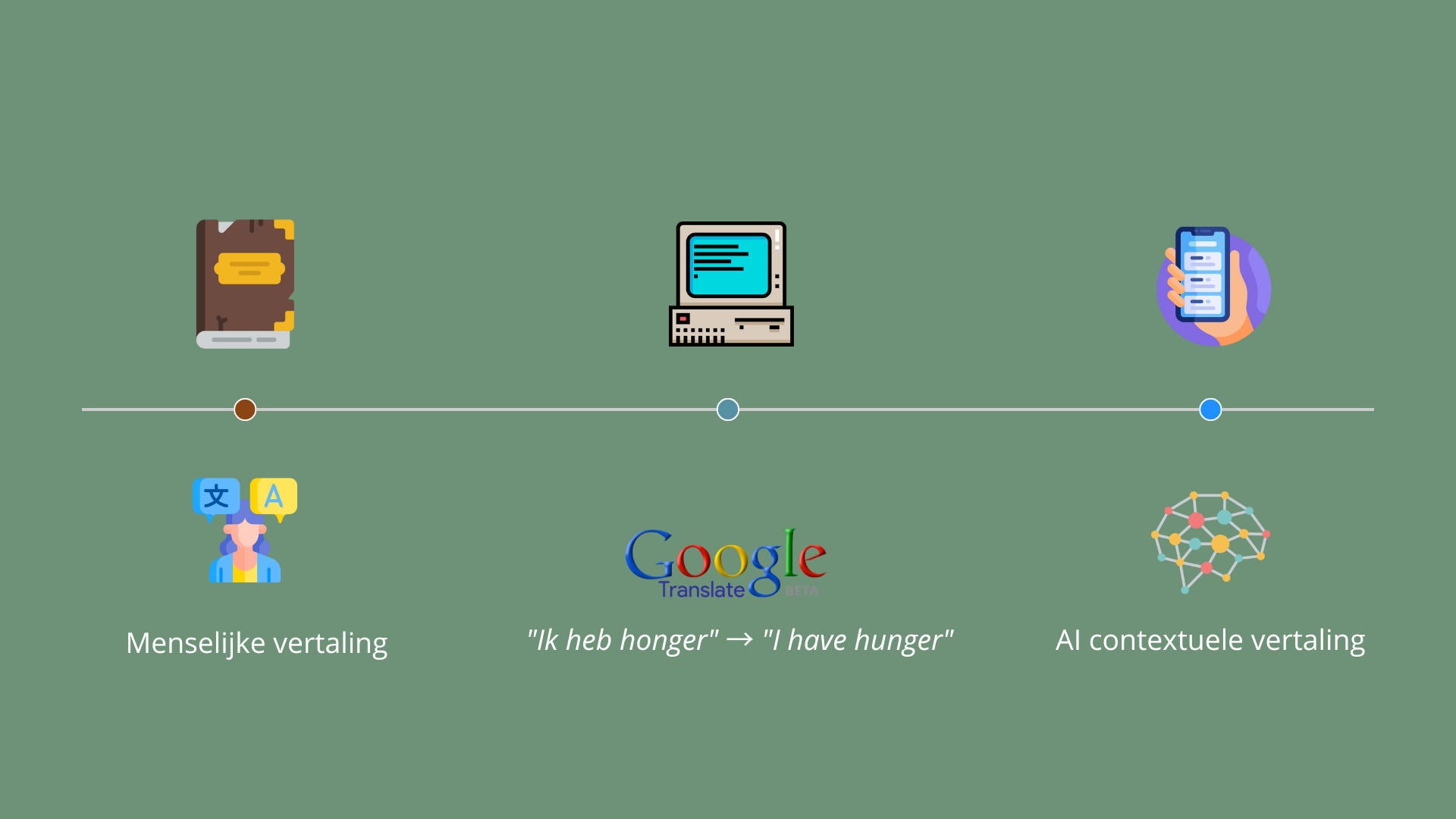
Van Google Translate naar ChatGPT
AI-taaltoepassingen bestaan al decennia. De eerste versies waren niet meer dan een stel “if-then” regels. 'Als je dit woord tegenkomt, vervang het dan door dat woord.' Google Translate was in die tijd vooral een digitaal woordenboek. Type 'ik heb honger', krijg 'I have hunger'. Technisch correct, maar geen native speaker zou het zo zeggen.
Toen kwamen de statistische modellen. Voor het eerst konden computers patronen herkennen in hoe mensen écht schrijven. Google Translate ging ineens 'I'm hungry' suggereren. Beter, maar nog steeds beperkt tot het vertalen van losse zinnen. Zodra het aankwam op context of nuance, ging het mis.
De echte revolutie kwam met BERT in 2018. Voor het eerst kon een taalmodel snappen dat 'bank' iets anders betekent in 'ik loop naar de bank' dan in 'ik zit op de bank'. Dit klinkt simpel, maar is ongelooflijk complex. Het model moet namelijk begrijpen dat mensen op meubels zitten en naar gebouwen lopen. Het moet de hele context van de zin meenemen in zijn analyse.
Van theorie naar praktijk
In 2018 bouwden we bij Bluetick al toepassingen met deze taalmodellen. Ons doel? Advocaten helpen om relevante rechtspraak te vinden door simpelweg hun zaak te beschrijven - in normale mensentaal, geen zoektermen. De scepsis was groot ('AI in de advocatuur?'), maar toen advocaten rechtszaken begonnen te winnen met uitspraken die ze via ons hadden gevonden, wisten we: dit werkt echt.
Het bijzondere was niet dat het systeem 'begreep' waar zaken over gingen - want dat deed het niet. Maar door geavanceerde patroonherkenning kon het wel verbanden leggen die met traditioneel zoeken onmogelijk waren. Een advocaat schreef over 'ontslag na een conflict op de werkvloer', en het systeem vond ook zaken over 'arbeidsovereenkomst beëindigd na ruzie met collega's' - puur omdat het had geleerd dat deze formuleringen vaak in vergelijkbare contexten voorkwamen.
Twee jaar later werden we overgenomen door een van Nederlands grootste juridische uitgevers. We zagen het potentieel van AI - al had niemand kunnen voorspellen hoe groot de impact zou worden met de komst van ChatGPT.
Hoe werkt het nou echt?
Na alle hype rond ChatGPT vraagt iedereen zich af: hoe werkt dit nou eigenlijk? Het antwoord is verrassend simpel én complex tegelijk. Een Large Language Model doet eigenlijk maar één ding: het voorspelt steeds wat het volgende woord in een zin zou kunnen zijn.
Stel je voor: je krijgt een half afgemaakt Nederlands gedicht. 'De zon schijnt fel op het water, de golven glinsteren in het...' Zelfs als je geen dichter bent, kun je waarschijnlijk wel voorspellen dat hier 'licht' of 'zonlicht' zou kunnen komen. Je hebt immers duizenden Nederlandse zinnen gelezen in je leven. Je 'voelt' wat past.
Een LLM doet precies hetzelfde, maar dan met een dataset van miljarden teksten. Als je vraagt 'Wat is de hoofdstad van Frankrijk?', dan voorspelt het model: 'De hoofdstad van Frankrijk is...' en de meest waarschijnlijke volgende woorden zijn natuurlijk 'Parijs'. Niet omdat het 'weet' dat Parijs de hoofdstad is, maar omdat het dit patroon talloze keren heeft gezien.
Het wordt nog interessanter bij complexere vragen. Stel je vraagt 'Wat zijn de juridische vereisten voor een rechtsgeldige handtekening?'. Het model construeert een antwoord niet vanuit werkelijk juridisch inzicht, maar door patronen te herkennen uit talloze contractteksten. Het ziet hoe juridische professionals specifieke formuleringen gebruiken rond handtekeningvereisten, zoals 'Een rechtsgeldige handtekening dient te voldoen aan de volgende criteria...' en reproduceert die structuur - woord voor woord - zonder de onderliggende juridische mechaniek werkelijk te doorgronden.

Het gevaar van overtuigende leugens
Dit verklaart meteen waarom ChatGPT soms zo overtuigend klinkt, maar toch complete onzin kan uitkramen. Het model voorspelt simpelweg wat mensen waarschijnlijk zouden zeggen in een bepaalde context - of dat nou waar is of niet.
Het meest fascinerende - en mogelijk gevaarlijke - aspect van ChatGPT is dat het is getraind om altijd een antwoord te geven. Net als die ene vriend die nooit durft toe te geven dat hij iets niet weet. Vraag je 'Wat is de hoofdstad van het niet-bestaande land Zanopia?', dan zal het vrolijk een verzonnen antwoord geven. Niet omdat het liegt, maar omdat het is getraind om patronen te volgen van hoe mensen over hoofdsteden praten.
Dit maakt ChatGPT tegelijk briljant en gevaarlijk. Briljant omdat het altijd probeert te helpen en daardoor verrassend creatieve oplossingen kan bedenken. Gevaarlijk omdat het net zo overtuigend klinkt wanneer het de plank volledig misslaat als wanneer het gelijk heeft.
Dus de volgende keer dat je leest over een 'revolutionair nieuw AI-model', weet je: het is in essentie gewoon een extreem geavanceerde autocomplete. Maar net zoals een Instagram-filter geen fotografiekennis nodig heeft om prachtige foto's te maken, kan deze 'domme' technologie verrassend waardevol zijn.
Hoeveel mensen in jouw organisatie zijn dagelijks bezig met het herkennen van patronen en het formuleren van standaardresponses? En nog belangrijker: wat doe je als blijkt dat een systeem zonder 'echt begrip' daar effectiever in is?
Terwijl de AI-ontwikkelingen over elkaar heen blijven buitelen, help ik je niet alleen het overzicht te bewaren, maar ook om de échte kansen voor jouw organisatie te identificeren. Abonneer je op deze nieuwsbrief en deel hem met anderen die ook willen weten hoe ze AI succesvol kunnen implementeren - ondanks de beperkingen.
Tot slot: jij kan helpen bepalen waar de volgende edities over gaan. Waar loop jij tegenaan bij het implementeren van AI? Stuur me een bericht met jouw uitdaging - de belangrijkste vraagstukken behandel ik in de volgende edities.